
在前面以Docker项目为例,一步步剖析了Linux容器的具体实现方式。
通过这些应该明白:一个“容器”,实际上是一个由Linux Namespace、Linux Cgroups和rootfs三种技术构建出来的进程的隔离环境。
一个正在运行的Linux容器,其实可以被看做
- 一组联合挂载在 /var/lib/docker/aufs/mnt 上的rootfs,这部分称为“容器镜像”(Container Image),是容器的静态视图
- 一个由Namespace+Cgroups构成的隔离环境,这部分称为“容器运行时”(Container Runtime),是容器的动态视图。
作为一名开发者,我并不关心容器运行时的差异。
因为,在整个“开发-测试-发布”的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。
这个重要假设,正是容器技术圈在Docker项目成功后不久,就迅速走向了“容器编排”这个“上层建筑”的主要原因:
作为云基础设施提供商,只要能够将用户提交的Docker镜像以容器的方式运行,就能成为容器生态图上的一个承载点,从而将整个容器技术栈上的价值,沉淀在这个节点上。
更重要的是,只要从我这个承载点向Docker镜像制作者和使用者方向回溯,整条路径上的各个服务节点
比如CI/CD、监控、安全、网络、存储等,都有我可以发挥和盈利的余地。
这个逻辑,正是所有云计算提供商如此热衷于容器技术的重要原因:通过容器镜像,它们可以和开发者关联起来。
从一个开发者和单一的容器镜像,到无数开发者和庞大容器集群,容器技术实现了从“容器”到“容器云”的飞跃,标志着它真正得到了市场和生态的认可。
容器从一个开发者手里的小工具,一跃成为了云计算领域的绝对主角 而能够定义容器组织和管理规范的“容器编排”技术,坐上了容器技术领域的“头把交椅”
最具代表性的容器编排工具,当属
- Docker公司的Compose+Swarm组合
- Google与RedHat公司共同主导的Kubernetes项目
在前面介绍容器技术发展历史中,已经对这两个开源项目做了详细地剖析和评述。所以,在今天专注于主角Kubernetes项目,谈一谈它的设计与架构。
跟很多基础设施领域先有工程实践、后有方法论的发展路线不同,Kubernetes项目的理论基础则要比工程实践走得靠前得多,这当然要归功于Google公司在2015年4月发布的Borg论文了。
Borg系统,一直以来都被誉为Google公司内部最强大的“秘密武器”。
相比于Spanner、BigTable等相对上层的项目,Borg要承担的责任,是承载Google整个基础设施的核心依赖。
在Google已经公开发表的基础设施体系论文中,Borg项目当仁不让地位居整个基础设施技术栈的最底层。
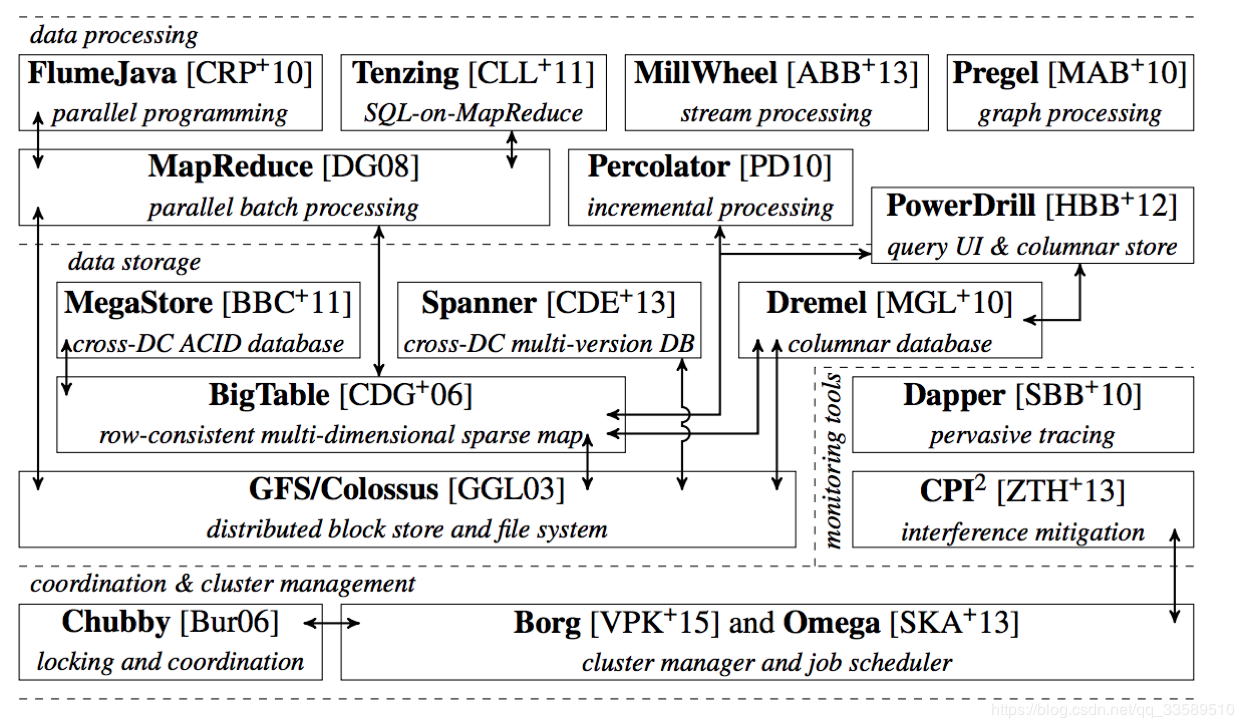
这幅图,来自于Google Omega论文的第一作者的博士毕业论文。它描绘了当时Google已经公开发表的整个基础设施栈。在这个图里,你既可以找到MapReduce、BigTable等知名项目,也能看到Borg和它的继任者Omega位于整个技术栈的最底层。
正是由于这样的定位,Borg可以说是Google最不可能开源的一个项目。
得益于Docker项目和容器技术的风靡,它却终于得以以另一种方式与开源社区见面,就是Kubernetes项目。
相比于“小打小闹”的Docker公司、“旧瓶装新酒”的Mesos社区,Kubernetes项目从一开始就比较幸运地站上了一个他人难以企及的高度:
在它的成长阶段,这个项目每一个核心特性的提出,几乎都脱胎于Borg/Omega系统的设计与经验。
更重要的是,这些特性在开源社区落地的过程中,又在整个社区的合力之下得到了极大的改进,修复了很多当年遗留在Borg体系中的缺陷和问题。
尽管在发布之初被批“曲高和寡”,但在逐渐觉察到Docker技术栈的“稚嫩”和Mesos社区的“老迈”,社区很快就明白了:Kubernetes项目在Borg体系的指导下,体现出了一种独有的先进与完备性,这些才是一个基础设施领域开源项目的核心价值。
从Kubernetes的顶层设计说起。
Kubernetes要解决什么?
编排?调度?容器云?还是集群管理?
至今其实都没有标准答案。在不同的发展阶段,Kubernetes需要着力的问题是不同的。
但对于大多数用户,他们希望Kubernetes项目带来的体验是确定的:
现在我有应用的容器镜像,请帮我在一个给定的集群上把应用运行起来
更进一步说,还希望Kubernetes能给我提供路由网关、水平扩展、监控、备份、灾难恢复等一系列运维能力。

这不就是经典PaaS(eg. Cloud Foundry)项目的能力吗!
而且,有了Docker后,根本不需要什么Kubernetes、PaaS,只要使用Docker公司的Compose+Swarm项目,就完全可以很方便DIY出这些功能!
所以说,如果Kubernetes项目只是停留在拉取用户镜像、运行容器,以及提供常见的运维功能的话,那别说跟嫡系的Swarm竞争,哪怕跟经典的PaaS项目相比也难有优势
而实际上,在定义核心功能过程中,Kubernetes项目正是依托着Borg项目的理论优势
才在短短几个月内迅速站稳了脚跟
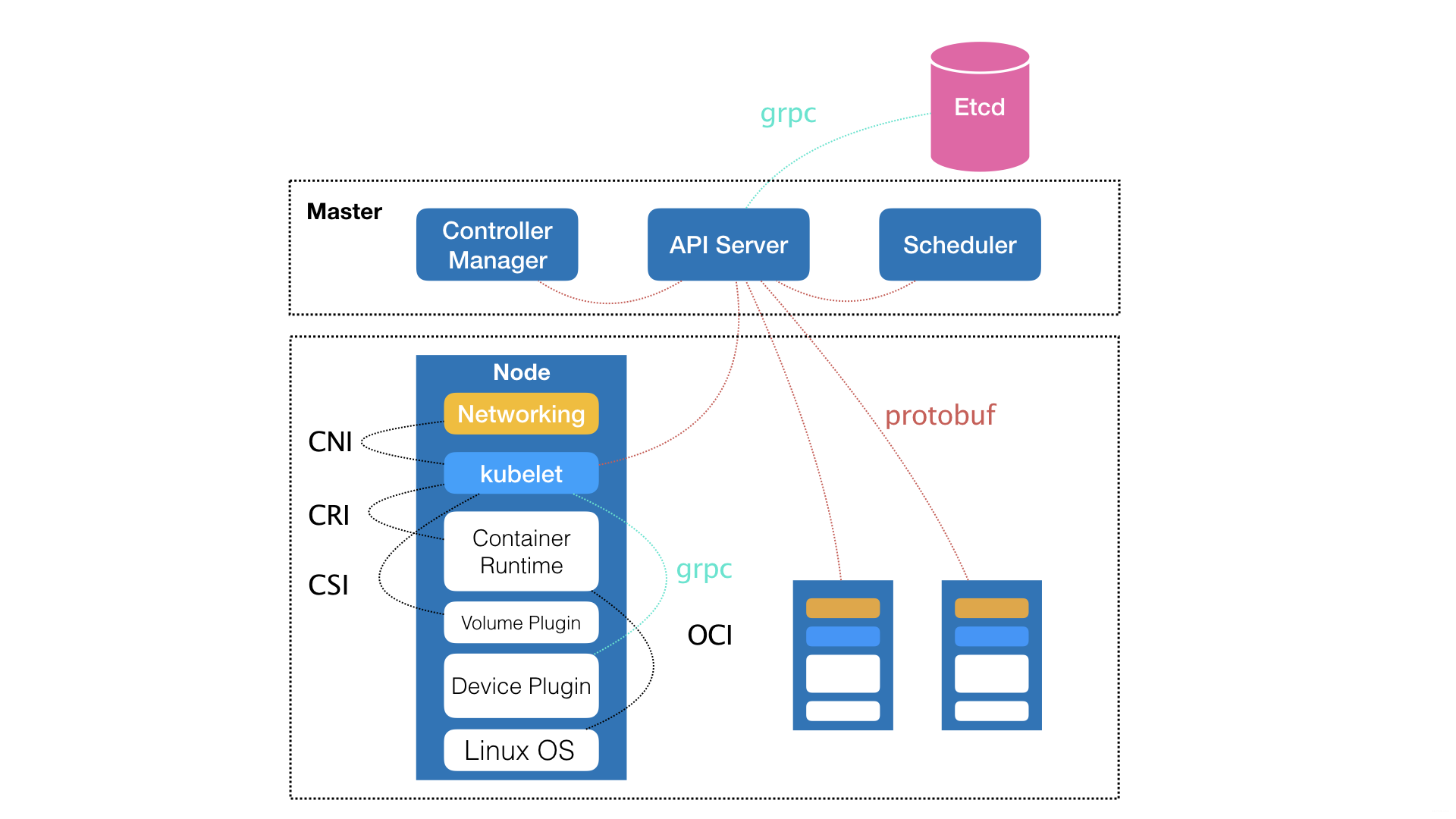
- 进而确定了一个如下所示的全局架构
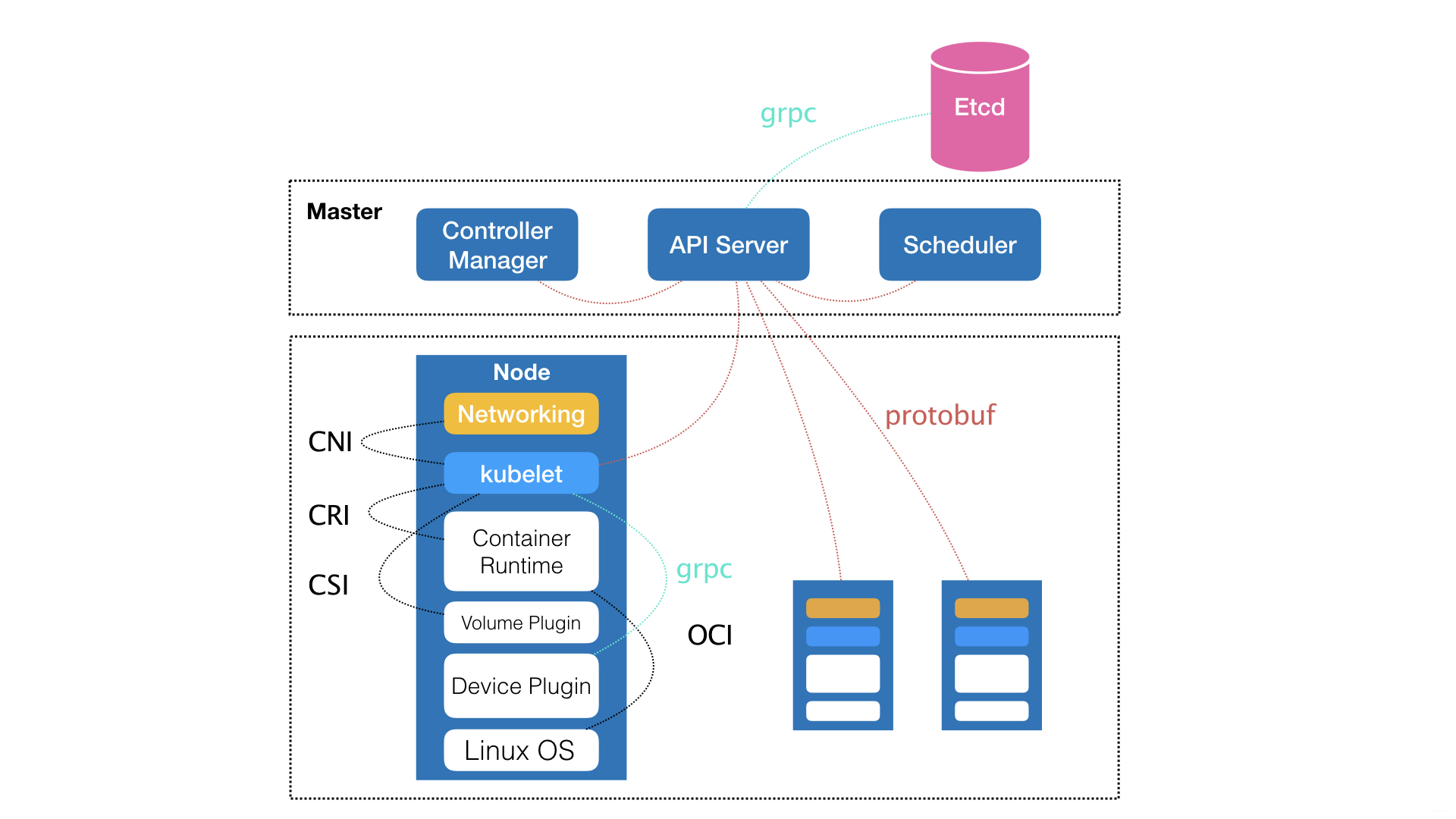
可以看到,Kubernetes项目的架构,跟它的原型项目Borg类似,都由Master和Node两种节点组成,分别对应着控制节点和计算节点。
其中,控制节点 --- 即Master节点,由三个紧密协作的独立组件组合而成,它们分别是
- 负责API服务的kube-apiserver
- 负责调度的kube-scheduler
- 负责容器编排的kube-controller-manager
整个集群的持久化数据,由kube-apiserver处理后保存在Ectd
而计算节点上最核心的是
kubelet组件
在Kubernetes中,kubelet主要负责同容器运行时(比如Docker项目)打交道。
而这个交互所依赖的,是一个称作 CRI(Container Runtime Interface) 的远程调用接口,这个接口定义了容器运行时的各项核心操作,比如:启动一个容器需要的所有参数。
这也是为何,Kubernetes项目并不关心你部署的是什么容器运行时、使用的什么技术实现,只要你的这个容器运行时能够运行标准的容器镜像,它就可以通过实现CRI接入到Kubernetes项目当中。
而具体的容器运行时,比如Docker项目,则一般通过OCI这个容器运行时规范同底层的Linux操作系统进行交互,即:把CRI请求翻译成对Linux操作系统的调用(操作Linux Namespace和Cgroups等)。
此外,kubelet还通过gRPC协议同一个叫作Device Plugin的插件进行交互。
这个插件,是Kubernetes项目用来管理GPU等宿主机物理设备的主要组件,也是基于Kubernetes项目进行机器学习训练、高性能作业支持等工作必须关注的功能。
而kubelet的另一个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。
这两个插件与kubelet进行交互的接口,分别是
- CNI(Container Networking Interface)
- CSI(Container Storage Interface)。
实际上,kubelet这个奇怪的名字,来自于Borg项目里的同源组件Borglet。
不过,如果你浏览过Borg论文的话,就会发现,这个命名方式可能是kubelet组件与Borglet组件的唯一相似之处。因为Borg项目,并不支持我们这里所讲的容器技术,而只是简单地使用了Linux Cgroups对进程进行限制。
这就意味着,像Docker这样的“容器镜像”在Borg中是不存在的,Borglet组件也自然不需要像kubelet这样考虑如何同Docker进行交互、如何对容器镜像进行管理的问题,也不需要支持CRI、CNI、CSI等诸多容器技术接口。
kubelet完全就是为了实现Kubernetes项目对容器的管理能力而重新实现的一个组件,与Borg之间并没有直接的传承关系。
虽然不使用Docker,但Google内部确实在使用一个包管理工具,名叫Midas Package Manager (MPM),其实它可以部分取代Docker镜像的角色。
Borg对于Kubernetes项目的指导作用又体现在哪里呢?
Master节点!
虽然在Master节点的实现细节上Borg与Kubernetes不尽相同,但出发点高度一致
即:如何编排、管理、调度用户提交的作业
所以,Borg项目完全可以把Docker镜像看做是一种新的应用打包方式。
这样,Borg团队过去在大规模作业管理与编排上的经验就可以直接“套”在Kubernetes项目。
这些经验最主要的表现就是,从一开始,Kubernetes就没有像同期的各种“容器云”项目,把Docker作为整个架构的核心,而是另辟蹊径, 仅仅把它作为最底层的一个容器运行时实现
而Kubernetes着重解决的问题,则来自于Borg的研究人员在论文中提到的一个非常重要的观点:
运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。
这种任务 <=>任务之间的关系随处可见
比如
- 一个Web应用与数据库之间的访问关系
- 一个负载均衡器和它的后端服务之间的代理关系
- 一个门户应用与授权组件之间的调用关系
而且同属于一个服务单位的不同功能之间,也完全可能存在这样的关系
比如
- 一个Web应用与日志搜集组件之间的文件交换关系。
而在容器技术普及之前,传统虚拟机对这种关系的处理方法都比较“粗粒度”
- 很多功能并不相关应用被一锅部署在同台虚拟机,只是因为偶尔会互相发几个HTTP请求!
- 更常见的情况则是,一个应用被部署在虚拟机里之后,你还得手动维护很多跟它协作的守护进程(Daemon),用来处理它的日志搜集、灾难恢复、数据备份等辅助工作。
在“功能单位”划分上,容器却有着独到的“细粒度”优势:
毕竟容器的本质,只是一个进程而已
就是说,只要你愿意,那些原挤在同一VM里的各个应用、组件、守护进程,都可被分别做成镜像!
然后运行在一个一个专属的容器中。
它们之间互不干涉,拥有各自的资源配额,可以被调度在整个集群里的任何一台机器上。
而这,正是一个PaaS系统最理想的工作状态,也是所谓微服务思想得以落地的先决条件。
如果只做到 封装微服务、调度单容器 这层次,Docker Swarm 就已经绰绰有余了。
如果再加上Compose项目,甚至还具备了处理一些简单依赖关系的能力
比如
- 一个“Web容器”和它要访问的数据库“DB容器”
在Compose项目中,你可以为这样的两个容器定义一个“link”,而Docker项目则会负责维护这个“link”关系
其具体做法是:Docker会在Web容器中,将DB容器的IP地址、端口等信息以环境变量的方式注入进去,供应用进程使用,比如:
DB_NAME=/web/db
DB_PORT=tcp://172.17.0.5:5432
DB_PORT_5432_TCP=tcp://172.17.0.5:5432
DB_PORT_5432_TCP_PROTO=tcp
DB_PORT_5432_TCP_PORT=5432
DB_PORT_5432_TCP_ADDR=172.17.0.5
- 平台项目自动地处理容器间关系的典型例子
当DB容器发生变化时(比如镜像更新,被迁移至其他宿主机),这些环境变量的值会由Docker项目自动更新
可是,如果需求是,要求这个项目能够处理前面提到的所有类型的关系,甚至能
支持未来可能的更多关系
这时,“link”这针对一种案例设计的解决方案就太过简单了
一旦要追求项目的普适性,那就一定要从顶层开始做好设计
Kubernetes最主要的设计思想是,从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地。
比如,Kubernetes对容器间的“访问”进行了分类,首先总结出了一类常见的“紧密交互”的关系,即:
- 应用之间需要非常频繁的交互和访问
- 会直接通过本地文件进行信息交换
常规环境下的应用往往会被直接部在同一台机器,通过Localhost通信,通过本地磁盘目录交换文件
而在Kubernetes,这些容器会被划分为一个“Pod”
Pod里的容器共享同一个Network Namespace、同一组数据卷,从而达到高效率交换信息的目的。
Pod是Kubernetes中最基础的一个对象,源自于Google Borg论文中一个名叫Alloc的设计

Borg分配(分配的缩写)是一台机器上可以运行一个或多个任务的资源的保留集。无论是否使用资源,资源都会保持分配状态。 Alloc可用于为将来的任务留出资源,在停止任务和重新启动任务之间保留资源,以及将来自不同作业的任务收集到同一台计算机上–例如,一个Web服务器实例和一个关联的logaver任务,用于复制服务器的URL日志从本地磁盘记录到分布式文件系统。分配资源与机器资源的处理方式相似。在一个内部运行的多个任务共享其资源。如果必须将分配重定位到另一台计算机,则其任务将随之重新安排。
分配集就像一项工作:它是一组在多台机器上保留资源的分配。创建分配集后,可以提交一个或多个作业以在其中运行。为简便起见,我们通常使用“任务”来指代分配或顶级任务(在分配外的一个),使用“作业”来指代作业或分配集。
而对于另外一种更为常见的需求,比如
Web应用与数据库之间的访问关系
Kubernetes则提供了一种叫作“Service”的服务。像这样的两个应用,往往故意不部署在同一机器,即使Web应用所在的机器宕机了,数据库也不受影响。
可对于一个容器来说,它的IP地址等信息是不固定的,Web应用又怎么找到数据库容器的Pod呢?
所以,Kubernetes的做法是给Pod绑定一个Service服务
Service服务声明的IP地址等信息是“终生不变”的。Service主要就是作为Pod的代理入口(Portal),从而代替Pod对外暴露一个固定的网络地址。
这样,对于Web应用的Pod来说,它需要关心的就是数据库Pod的Service信息。不难想象,Service后端真正代理的Pod的IP地址、端口等信息的自动更新、维护,则是Kubernetes的职责。
围绕着容器和Pod不断向真实的技术场景扩展,我们就能够摸索出一幅如下所示
-
Kubernetes核心功能“全景图”
从容器这个最基础的概念出发,首先遇到了容器间“紧密协作”关系的难题,于是就扩展到了Pod
有了Pod之后,我们希望能一次启动多个应用的实例,这样就需要Deployment这个Pod的多实例管理器
而有了这样一组相同的Pod后,我们又需要通过一个固定的IP地址和端口以负载均衡的方式访问它,于是就有了Service
如果现在
两个不同Pod之间不仅有“访问关系”,还要求在发起时加上授权信息
最典型的例子就是Web应用对数据库访问时需要Credential(数据库的用户名和密码)信息。
那么,在Kubernetes中这样的关系又如何处理呢?
Kubernetes项目提供了一种叫作Secret的对象,是一个保存在Etcd里的键值对。
这样,你把Credential信息以Secret的方式存在Etcd里,Kubernetes就会在你指定的Pod(比如,Web应用Pod)启动时,自动把Secret里的数据以Volume的方式挂载到容器里。这样,这个Web应用就可以访问数据库了。
除了应用与应用之间的关系外,应用运行的形态是影响“如何容器化这个应用”的第二个重要因素。
为此,Kubernetes定义了基于Pod改进后的对象。比如
- Job
描述一次性运行的Pod(比如,大数据任务) - DaemonSet
描述每个宿主机上必须且只能运行一个副本的守护进程服务 - CronJob
描述定时任务
如此种种,正是Kubernetes定义容器间关系和形态的主要方法。
Kubernetes并没有像其他项目那样,为每一个管理功能创建一个指令,然后在项目中实现其中的逻辑
这种做法,的确可以解决当前的问题,但是在更多的问题来临之后,往往会力不从心
相比之下,在Kubernetes中,我们推崇
- 首先,通过一个“编排对象”,比如Pod/Job/CronJob等描述你试图管理的应用
- 然后,再为它定义一些“服务对象”,比如Service/Secret/Horizontal Pod Autoscaler(自动水平扩展器)等。这些对象,会负责具体的平台级功能。
这种使用方法,就是所谓的“声明式API”。这种API对应的“编排对象”和“服务对象”,都是Kubernetes中的API对象(API Object)。
这就是Kubernetes最核心的设计理念,也是接下来我会重点剖析的关键技术点。
Kubernetes如何启动一个容器化任务
现在已经制作好了一个Nginx容器镜像,希望让平台帮我启动这个镜像。并且,我要求平台帮我运行两个完全相同的Nginx副本,以负载均衡的方式共同对外提供服务。
如果DIY,可能需要启动两台虚拟机,分别安装两个Nginx,然后使用keepalived为这两个虚拟机做一个虚拟IP。
而如果使用Kubernetes呢?要做的则是编写如下这样一个YAML文件(比如名叫nginx-deployment.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
在上面这个YAML文件中,定义了一个Deployment对象,它的主体部分(spec.template部分)是一个使用Nginx镜像的Pod,而这个Pod的副本数是2(replicas=2)。
然后执行:
$ kubectl create -f nginx-deployment.yaml
这样,两个完全相同的Nginx容器副本就被启动了。
不过,这么看来,做同样一件事情,Kubernetes用户要做的工作也不少啊
别急,在后续会陆续介绍Kubernetes这种“声明式API”的好处,以及基于它实现的强大的编排能力。
总结
首先,一起回顾了容器的核心知识,说明了容器其实可以分为两个部分
- 容器运行时
- 容器镜像
然后,重点介绍了Kubernetes的架构,详细讲解了它如何使用“声明式API”来描述容器化业务和容器间关系的设计思想。
调度
过去很多的集群管理项目(比如Yarn、Mesos,以及Swarm)所擅长的,都是把一个容器,按照某种规则,放置在某个最佳节点上运行起来。这种功能,称为“调度”。
编排
而Kubernetes所擅长的,是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系。
这种功能,就是我们经常听到的一个概念:编排。
所以说,Kubernetes的本质,是为用户提供一个具有普遍意义的容器编排工具。
Kubernetes为用户提供的不仅限于一个工具。它真正的价值,还是在于提供了一套基于容器构建分布式系统的基础依赖
参考
- 深入剖析Kubernetes
- Large-scale cluster management at Google with Borg
